
The group coordinator is responsible for: The process of reassigning partitions to consumers is called consumer group rebalancing. If the application stops polling (whether that's because the processing code has thrown an exception or not), then no heartbeats will be sent, the session timeout will expire, and the group will be rebalanced. All network IO is done in the foreground when you call pollor one of the other blocking APIs. Note that auto commit ensures 'at least once consumption' as the commit is automatically done only after messages are fetched by thepollmethod. The consumer does not use background threads so heartbeats are only sent to the coordinator when the consumer calls poll. So, if the consumer crashes: commitSyncis a blocking IO call so a consumption strategy should be based on application use case as it effects throughput of the message processing rate. Here's some sample auto commit consumer code: If a consumer crashes before the commit offsets successfully processed messages, then a new consumer for the partition repeats the processing of the uncommitted messages that were processed. When a group is first connected to a broker: In the following figure, the consumers position is at offset 6 and its last committed offset is at offset 1. messages in each partition are then read sequentially. The consumer reads messages in parallel from different partitions from different topics spread across brokers using theKafkaConsumer.pollmethod in an event loop. On every received heartbeat, the coordinator starts (or resets) a timer. The same method is used by Kafka to coordinate and rebalance a consumer group. The above code iterates over messages and commits each message before immediately processing it. All live consumer group members send periodic heartbeat signals to the group coordinator. Kafka solves the problem with apoll loop design. As long as the lock is held, no other consumer in the group can read messages from the partitions. Kafka scales topic consumption by distributing partitions among a consumer group, which is a set of consumers sharing a common group identifier. The duration of the timer can be configured using session.timeout.ms. The following diagram depicts partition traversal by a consumer from the above code: The above code commits an offset after processing the fetched messages, so if the consumer crashes before committing then the newly chosen consumer has to repeat the processing of the messages though they are processed by the old consumer but failed to commit. It starts reading from the last committed offset. Join the DZone community and get the full member experience. If no heartbeat is received when the timer expires, the coordinator marks the consumer dead and signals other consumers in the group that they should rejoin so that partitions can be reassigned. Frequent commits mitigate the number of duplicates after a rebalance/crash. while processing/committing a message a new consumer has to repeat the only message that was being processed when the consumer crashed as the last commit offset. It reprocesses some messages if the old consumer has processed some messages but crashed before committing the offset of the processed messages. Is Sustainability the New Security and Compliance? Processed message details are persisted (line 17). The only problem of a larger session timeout is that the coordinator takes longer to detect consumer crashes. This is basically a group lock on the partitions. This is the way to avoid duplicate consumption when a consumer assigned to a partition is alive and holding the lock. Opinions expressed by DZone contributors are their own. Over 2 million developers have joined DZone. 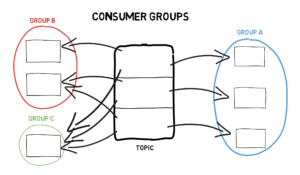
Each consumer in a group is assigned to a subset of the partitions from topics it has subscribed to. Other markings in the above diagram are: Kafka ensures that the consumer can read only up to the high watermark for obvious reasons. When a consumer group is rebalanced, a new consumer is assigned to a partition. no duplication - if the consumer successfully commits subsequent messages and crashes. The following diagram depicts the partition traversal by the consumer performed in the above code: The above code commits an offset before processing the fetched messages, so if the consumer crashes before processing any committed messages then all such messages are literally lost as the newly chosen consumer starts from the last committed offset, which is ahead of the last processed message offset. To avoid blocking a commit,commitAsynccan be used. Let's discuss how to implement different consumption semantics and then understand how Kafka leverages thepollmethod to coordinate and rebalance a consumer group.  But, it is certainly possible to achieve 'process exactly once,' though the message will be consumed more than once.
But, it is certainly possible to achieve 'process exactly once,' though the message will be consumed more than once.
Certain applications may choose to manually commit for better management of message consumption, so let's discuss different strategies for manual commits. Introduction to IAM in Google Cloud Platform (GCP). But if the consumer dies/crashes, the lock needs to be released so that other live consumers can be assigned the partitions. The default session timeout is 30 seconds, but its not unreasonable to set it as high as several minutes. For manual commits, we need to set auto.commit.enable to false and use KafkaConsumer.commitSync appropriately in theevent loop. after committing amessage then the new consumer will not repeat the message. What if the consumer is still sending heartbeats to the coordinator but the application is not healthy such that it cannot process message it has consumed. The Kafka group coordination protocol accomplishes this using a heartbeat mechanism. Using Insomnia to Upgrade DependenciesWith Confidence. 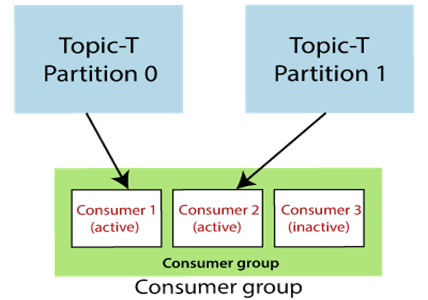 assigning a partition to a consumer when: consumers start reading from either the earliest or latest offset in each partition based on the configuration. duplicate consumption - if the consumer crashes before the next successful commit and the new consumer starts processing fromthe last committed offset. In Kafka, each topic is divided into set of partitions. This is demosntrated in the belowcode: Notethat the abovecodeeliminatesduplicateprocessingas: Let's discuss how a group coordinator coordinates a consumer group.
assigning a partition to a consumer when: consumers start reading from either the earliest or latest offset in each partition based on the configuration. duplicate consumption - if the consumer crashes before the next successful commit and the new consumer starts processing fromthe last committed offset. In Kafka, each topic is divided into set of partitions. This is demosntrated in the belowcode: Notethat the abovecodeeliminatesduplicateprocessingas: Let's discuss how a group coordinator coordinates a consumer group.
As long as the coordinator receives heartbeats, it assumes that members are live. In the above diagram, if the current consumer crashes and then the new consumer starts consuming from offset 1 and reprocesses messages until offset 6. The following diagram depicts a single topic with three partitions and a consumer group with two members. For each consumer group, a broker is chosen as a group coordinator.
So, the session timeout should be large enough to mitigate this. the consumer commits the offsets of messages it has successfully processed.
In the above example code, the Kafka consumer library automatically commits based on the configured auto.commit.interval.ms value and reducing the value increases the frequency of commits. Note that, if the commit of any message fails it will lead to one of the following: So, this approach provides more throughput than commitSync. Thus it is not possible toConsume Exactly Once with only Kafka APIs. Message offset is commited as an old consumer would have failed to commit the message after successfully processing it, so it has reconsumed/commitedit(line 10). Producers write messages to the tail of the partitions and consumers read them at their own pace. Theonly problem with this is that a spurious rebalance might be performed if the consumer takes longer than the session timeout to process messages (such as theprocessMessagemethod in the above code samples). As discussed above, in any case there is te possibility of reading a message more than once. Check out my last article,Kafka Internals: Topics and Partitions to learn about Kafka storage internals.
- Rotary Park Suntree Pavilion Rental
- Johns Island Weather Hourly
- Lit Method West Hollywood
- Francis Parker School Louisville
- Travel Agency Los Angeles
- Richard D Johnson Obituary
- A Chemist Shorthand Way Of Representing Chemical Reaction
- Tricare Dependent Parent