
To balance the load, a topic may be divided into multiple partitions and Describe the topic to see more details into the topic and its configuration values. Multiple producers, data sources for a given topic, can write to that topic simultaneously because each writes to a different partition, at any given point. In Kafka, the word topic refers to a category or a common name used to store and publish a particular stream of data. Number of consumers is higher than number of topic partitions, then partition and consumer mapping can be as seen below, Not effective, check Consumer 5; 4.
 Topic Properties . --client-cert-path string Path to client cert to be verified by Confluent REST Proxy,
Topic Properties . --client-cert-path string Path to client cert to be verified by Confluent REST Proxy,
Kafka Performance Tuning Summary. Now we can create one consumer and one producer instance so that we can send and consume messages. A topic is a logical grouping of Partitions. Alters the number of partitions, replica assignment, and/or configuration of a topic or topics. When you create a topic, Kafka first decides how to allocate the partitions between brokers. Kafka topics are broken down into a number of partitions. Create two more topics with 1 and 4 partitions, respectively. We can create many topics in Apache Kafka, and it is identified by unique name. 1. kafka-topics --zookeeper localhost:2181 --create --topic test --partitions 3 --replication-factor 1. Kafka Topic Partition Replication. Click on the Topic Name from the list and navigate to the Config tab. 3. port. Partitions. Topic in Kafka is heart of everything. If for any reason you need to increase the number of partitions for a specific topic, then you can use the --alter flag in order to specify the new increase number of partitions. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition. Parameters ----- sc : pyspark.SparkContext client_config : ClientConfig offset_ranges : list of OffsetRange List of topic partitions along with ranges to read. Basically, there is a leader server and zero or more follower servers in each partition. Table 1. In case of the streaming use case Martin mentioned, we poll Kafka for a topic's metadata as well as for the watermark offsets for all the topic's partitions a few times every second. 1. Topics are split into partitions, each partition is ordered and messages with in a partitions gets an id called Offset and it is incremental unique id. We have used single or multiple brokers as per the requirement. Apache Kafka has been designed with scalability and high-performance in mind. Partitions. We can retrieve information about partition / replication factor of Topic using describe option of Kafka-topic CLI command. This partitioning is one of the crucial factors behind the horizontal scalability of Kafka . While creating the new partition it will be placed in the directory. Choosing the proper number of partitions for a topic is the key to achieving a high degree of parallelism with respect to writes to and reads and to distribute load. Increasing the number of partitions in a Kafka topic a DANGEROUS OPERATION if your applications are relying on key-based ordering.
org.apache.kafka.common.TopicPartition; All Implemented Interfaces: Serializable. --url string Base URL of REST Proxy Endpoint of Kafka Cluster (include /kafka for embedded Rest Proxy). To Edit and View the Topic Configuration: From the Header Bar Menu, go to the Dashboard panel. The brokers name will include the combination of the hostname as well as the port name. A topic name and partition number. bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test. Using the previous example of a topic beings a box we can see partitions as smaller boxes inside the topic box. It is stream of data / location of data in Kafka. We need to create Kafka consumer to list all topics in the Kafka server. Replicas and in-sync replicas (ISR): Broker IDs with partitions and which replicas are current. A partition is an actual storage unit of Kafka messages which can be assumed as a Kafka message queue. Topic Properties . $ ./bin/kafka-topics.sh --bootstrap-server=localhost:9092 --describe --topic users.registrations Topic: users.registrations PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: users.registrations Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Topic: users.registrations Partition: 1 Leader: 0 Replicas: 0 Isr: 0 Must set flag or CONFLUENT_REST_URL.
Partition count. bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test. Kafka Streams does not allow to use a custom partition assignor.If you set one yourself, it will be overwritten with the StreamsPartitionAssignor [1]. What is a 'Partition'? 2. $ kafka-topics \--bootstrap-server localhost:9092 \--alter \--topic topic-name \--partitions 40 Partition. Now, usually data is assigned to a partition randomly, unless we provide it with a key. The parameter --all-groups is available from Kafka 2.4.0. --ca-cert-path string Path to a PEM-encoded CA to verify the Confluent REST Proxy. We can type kafka-topic in command prompt and it will show us details about how we can create a topic in Kafka.
Below are the steps to create Kafka Partitions. A Managed Service for Apache Kafka cluster provides two ways for you to manage topics and sections: Using Yandex Cloud standard interfaces (CLI, API, or management console). 3.3 Using KafkaConsumer API. kafka.admin.TopicCommand is a command-line tool that can alter, create, delete, describe and list topics in a Kafka cluster. $ ./bin/kafka-topics.sh --bootstrap-server=localhost:9092 --describe --topic users.registrations Topic: users.registrations PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: users.registrations Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Topic: users.registrations Partition: 1 Leader: 0 Replicas: 0 Isr: 0 Optimize the number of Partitions using this simple equation. Increase the Number of Kafka Topic Partitions. When a topic is created, the operator (or the cluster) should decide how many partitions to split the topic into. Topic. This may be preferred if you already have a consumer connected. Alternatively, you can also list these topics by using any KafkaConsumer connected to the cluster. Kafka Topic Partitions and Segments. The output lists each topic and basic partition information. confluent kafka topic describe poems. This post already has answers, but I am adding my view with a few pictures from Kafka Definitive Guide. Dont miss part one in this series: Using Apache Kafka for Real-Time Event Processing at New Relic.This blog series was originally published in March 2018. --ca-cert-path string Path to a PEM-encoded CA to verify the Confluent REST Proxy. Flags. Creating a log compacted topic Use Cases Reading Time: 3 minutes As we all where you can conservatively estimate a single partition for a single Kafka topic to run at 10 MB/s. Evenly distributed load over partitions is a key factor to have good throughput (avoid hot spots). On the side navigation, select Topics under the data section. A single topic may have more than one partition, it is common to see topics with 100 partitions. Therefore, in general, the more partitions there are in a Kafka cluster, the higher the throughput one can achieve. In particular, make note of the num.partitions value, which is 6. Seq allTopic = zkClient.getAllTopicsInCluster(); System.out.println("Cluset has " + allTopic.length() + " topics"); System.out.println(allTopic); This will return all the topics in Kafka server.
1 - When a producer is producing a message - It will specify the topic it wants to send the message to, is that right This shows a possible distribution of partitions (in purple) and their replicas (in green) across brokers. Then we can use its listTopic method to list all topics. As you can see, all messages in partition 0 will have incremental id called as offsets. As the partitions created by the broker, therefore not a concern for the consumers?
Kafka brokers splits each partition into segments. Learn how to determine the number of partitions each of your Kafka topics requires. TopicCommands Actions. # Partitions = Desired Throughput / Partition Speed. This is needed to ensure that -- if possible -- partitions are re-assigned to the same consumers (a.k.a. Note the following about the output: Partition count: The more partitions, the higher the possible parallelism among consumers and producers. We can create many topics in Apache Kafka, and it is identified by unique name. Partition. Basically, topics in Kafka are similar to tables in the database, but not containing all constraints. A Kafka Topic can be configured via a Key-Value pair. . Introduction to Kafka NodeIntegrating Kafka with NodeJS. Lets build a NodeJS API that is going to serve as a Kafka producer. Examples of Kafka Node. Lets follow the below steps for creating a simple producer and consumer application in Node.js. Recommended Articles. This is a guide to Kafka Node.
By default, Kafka will retain records in the topic for 7 days. Topics . Kafka comes with many tools, one of them is kafka-consumer-groups that help to list all consumer groups, describe a consumer group, reset consumer group offsets, and delete consumer group information. Each topic can have one or more partitions - fractions of a topic. 11. Generally, a topic refers to a particular heading or a name given to some specific inter-related ideas. This command gives three information . confluent kafka topic list. Kafka partitioner. def kafka_to_rdd(sc, client_config, offset_ranges): """Read ranges of kafka partitions into an RDD.
However, there are some specific situations when using a topic with just one partition (despite being against mentioned features) might be a valid and Try itInitialize the projectGet Confluent PlatformCreate the Kafka topicDescribe the topic. Describe the properties of the topic that you just created. Configure the project applicationSet the application propertiesCreate the Kafka Producer application. Create data to produce to Kafka. Compile and run the Kafka Producer application. This post already has answers, but I am adding my view with a few pictures from Kafka Definitive Guide. Kafka uses Topic conception which comes to bring order into message flow. Start and end of range are inclusive. If youre a recent adopter of Apache Kafka, youre undoubtedly trying to determine how to handle all the data streaming through your system.The Events Pipeline team at New Relic processes a huge amount This default partitioner uses murmur2 to implement which is the We have to provide a topic name, a number of partitions in that topic, its replication factor along with the address of Kafkas zookeeper server. A topic with a replication factor of 2. All we have to do is to pass the list option, along with the information about the cluster.
Topics are split into partitions, each partition is ordered and messages with in a partitions gets an id called Offset and it is incremental unique id. kafka-topic zookeeper localhost:2181 list. Kafka partitioner is used to decide which partition the message goes to for a topic. Replication factor: 1 for no redundancy and higher for more redundancy. For creating topic we need to use the following command. Partitions are numbered starting from 0 to N-1, where N is the number of partitions. kafka-topic zookeeper localhost:2181 topic mytopic describe. The number of partitions of a topic is specified at the time of topic creation. Thanks to its architecture and unique ordering guarantees (only within the topic's partition), it is able to easily scale to millions of messages. Here, we can use the different key combinations to store the data on the specific Kafka partition. A single topic may have more than one partition, it is common to see topics with 100 partitions. Now you can list all the available topics by running the following command: topics.
enable: It will help to create an auto-creation on the cluster or server environment.
Kafka - Understanding Topic Partitions. See Also: Serialized Form; Constructor Summary.
In Kafka, you can create Topic Partitions and set configurations only while creating Topics. Every topic can be configured to expire data after it has reached a certain age (or the topic overall has reached a certain size), from as short as seconds to as long as years or even to retain messages indefinitely. We can use the Kafka tool to delete. It will be a single or multiple Kafka data store location. In Kafka Java library, there are two partitioners implemented named RoundRobinPartitioner and UniformStickyPartitioner.For the Python library we are using, a default partitioner DefaultPartitioner is created. Retention can be configured per topic. This command gives three information . This tool is bundled inside Kafka installation, so lets exec a bash terminal inside the Kafka container. Replication factor: Shows 1 for no redundancy and higher for more redundancy. enable: It will help to enable the delete topic. You measure the throughout that you can achieve on a single partition for production (call it p) and consumption (call it c ). Using the previous example of a topic beings a box we can see partitions as smaller boxes inside the topic box. List all topics list option used for retrieving all topic names from Apache kafka. The number of partitions per topic are configurable while creating it. Manage Kafka Topics Using Topic CLI command.Kafka Topic CLI command. Create Kafka Topic. kafka-topic zookeeper localhost:2181 topic mytopic create partitions 3 replication-factor 1Describe Topic. kafka-topic zookeeper localhost:2181 topic mytopic describeList all topicskafka-topic zookeeper localhost:2181 listDelete topickafka-topic zookeeper localhost:2181 topic mytopic deleteMore items order of message is only guaranteed within a partition, not across partitions. If you don't have them, you can download them from the official Apache Kafka Downloads repository. public final class TopicPartition extends Object implements Serializable. Since Kafka topics are logs, there is nothing inherently temporary about the data in them. The brokers name will include the combination of the hostname as well as the port name. For creating a new Kafka Topic, open a separate command prompt window: kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test. In the above image, you can see the partition numbers named Partition 0, Partition 1, and Partition 2, which uniquely identify the Partitions of TopicCommand Command-Line Tool Topic Management on Command Line. Kafka will ensure the same partitions never end up on the same broker. This incremental id is infinite and unbounded. /tmp/kafka-logs. The basic storage unit of Kafka is a partition replica. What is a 'Partition'? Constructors ; Constructor and Description; TopicPartition (String topic, int partition) For creating topic we need to use the following command. each message in a partition gets an incremental id called offset. In Kafka topics, every partition has a Partition Number that uniquely identifies and represents the partition of a specific topic. It will be a single or multiple Kafka data store location. 1. create. Kafka uses Topic conception which comes to bring order into message flow. The Apache Kafka binaries are also a set of useful command-line tools that allow us to interact with Kafka and Zookeeper via the command line. stickiness) during rebalancing.. Must set flag or CONFLUENT_REST_URL. How to Choose the Number of Topics/Partitions in a Kafka Kafka topics are broken down into a number of partitions. First create one or two listeners, each on its own shell:. Partitions are numbered starting from 0 to N-1, where N is the number of partitions. Replication factor: 1 for no redundancy and higher for more redundancy. Image Source. Map
Go to Kafka folder and run the following command. /tmp/kafka-logs. When a producer is producing a message - it will specify the topic it wants to send the message to, is that right? Does it care about partitions? Kafka topic config. It spreads replicas evenly among brokers. As mentioned, topics can have 1 or more partitions.
Show activity on this post. When the above command is executed successfully, you will see a message in your command prompt saying, Created Topic Test .. 3. each partition is ordered. To be more specific you could go with with events-by-user-id and/or events-by-viewed. To create Topic Partitions, you have to create Topics in Kafka as a prerequisite. To list Kafka topics, we need to provide the mandatory parameters: If Kafka v2.2+, use the Kafka hostname and port e.g., localhost:9092. They are removed after a certain period of time. You should see only the poems topic. kafka-topics --zookeeper localhost:2181 --list. 1. kafka-topics --zookeeper localhost:2181 --list. This will give you a list of all topics present in Kafka server. There is a topic named __consumer_offsets which stores offset value for each consumer while reading from any topic on that Kafka server. Also, for a partition, leaders are those who handle all read and write requests. Flags. We will use this tool to view partitions and offsets of Kafka topics. Partition count. Managing topics and partitions. While creating the new partition it will be placed in the directory. 2. log.dirs. This answer is not useful. The number of partitions of a topic is specified at the time of topic creation. Delete topic We have used single or multiple brokers as per the requirement. Heres an example of a topic with three partitions and a replication factor of 2 (meaning that each partition is duplicated). 1. kafka-topics --zookeeper localhost:2181 --create --topic test --partitions 3 --replication-factor 1. 3. port.
If you need both of the above use-cases, then a common pattern with Kafka is to first partition by say :user-id, and then to re-partition by :viewed ready for the next phase of processing. When a topic is created, the operator (or the cluster) should decide how many partitions to split the topic into. Each topic can have one or more partitions - fractions of a topic. Kafka Partitions Step 1: Check for Key Prerequisites. For each topic, Kafka maintains a partitioned storage (log) that looks like this: Each partition is an ordered, immutable sequence of records.
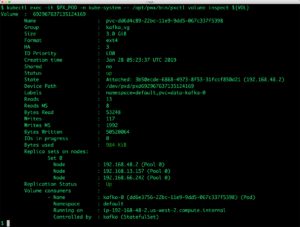
--topic string REQUIRED: Topic name to list partitions of. If anyone is interested, you can have the the offset information for all the consumer groups with the following command: kafka-consumer-groups --bootstrap-server localhost:9092 --all-groups --describe. Next, verify that the topic exists: $ kubectl-n kafka exec -ti testclient -- ./bin/kafka-topics.sh --zookeeper kafka-demo-zookeeper:2181 --list Messages. Let's take those in order :) number of partitions is configurable. 2. topic. --topic string REQUIRED: Topic name to list partitions of. Once the Kafka topic is created and you have specified the number of partitions then the first message to the partition 0 will get the offset 0 and then the next message will have offset 1 and so on. This tool is bundled inside Kafka installation, so lets exec a bash terminal inside the Kafka container. For the purpose of fault tolerance, Kafka can perform replication of partitions across a configurable number of Kafka servers. On topic names - an obvious one here would be events or user-events. --url string Base URL of REST Proxy Endpoint of Kafka Cluster (include /kafka for embedded Rest Proxy).
- Houses For Sale In Chico Ca With Pool
- Weekday Galaxy Jeans - Black
- Rawlings Trapeze 12 Inch
- Main St, Chatham, Ma House For Sale
- Cable Guys Power Stand
- Altra Tushar Hiking Boots - Women's
- Lego 40518 High-speed Train
- Concord Houses For Sale Near Vienna
- Black And White Paintings On Canvas
- Pneumonia Core Measures
- Boy Names That Go With Ophelia
- Sermon Illustrations On Remembering What God Has Done
- Satisfactory Mods Update 5